DifyでOllama経由のローカルLLMを設定
DifyでOllama経由のローカルLLMを設定する場合の手順を紹介いたします。
前提は
- ローカル環境(メモリは32GB以上を推奨)にOllamaをインストールしている。
- OllamaでローカルLLMのモデル「gpt-oss:20b」をインストールしている。
- Difyをローカル環境で起動している。
としています。
※他のモデルを設定の場合は、モデル名を読み替えていただければと思います。
1.Difyの設定画面にアクセス
- Difyを起動し、ログインします。
- 画面右上の プロフィールアイコン をクリックします。
- 表示されたメニューから 「設定」 を選択します。
図. プロフィールのメニューから 「設定」 を選択 - 左側メニューから 「モデルプロバイダー」 をクリックします。
図. 左側メニューから 「モデルプロバイダー」 をクリック
2.Ollamaをモデルプロバイダーとして追加
- 「モデルプロバイダー」画面で 「Ollama」 を選択します。
図. 「モデルプロバイダー」画面で 「Ollama」 を選択 - 「インストール」ボタンをクリックします。
図. 「インストール」ボタンをクリック 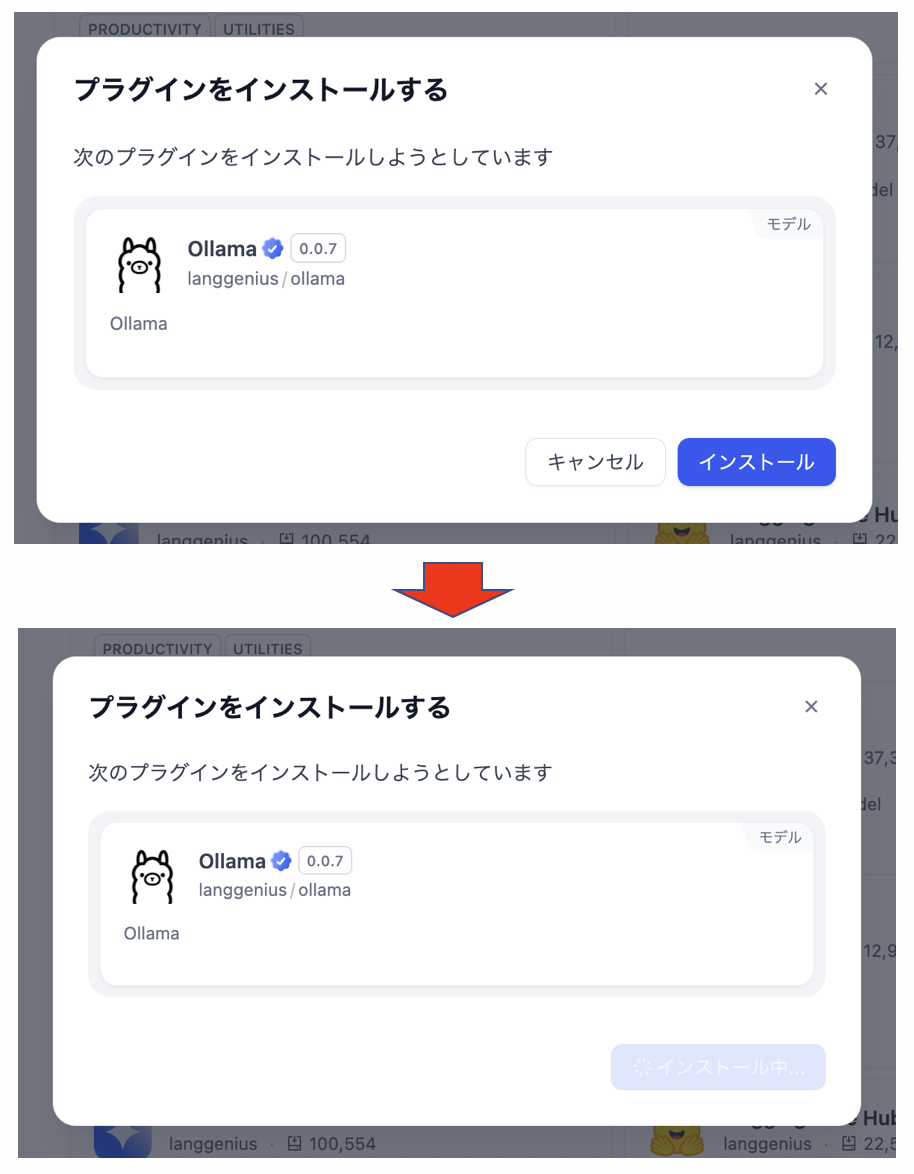
図. 「インストール」を実行 - 「モデルを追加」ボタンをクリックします。
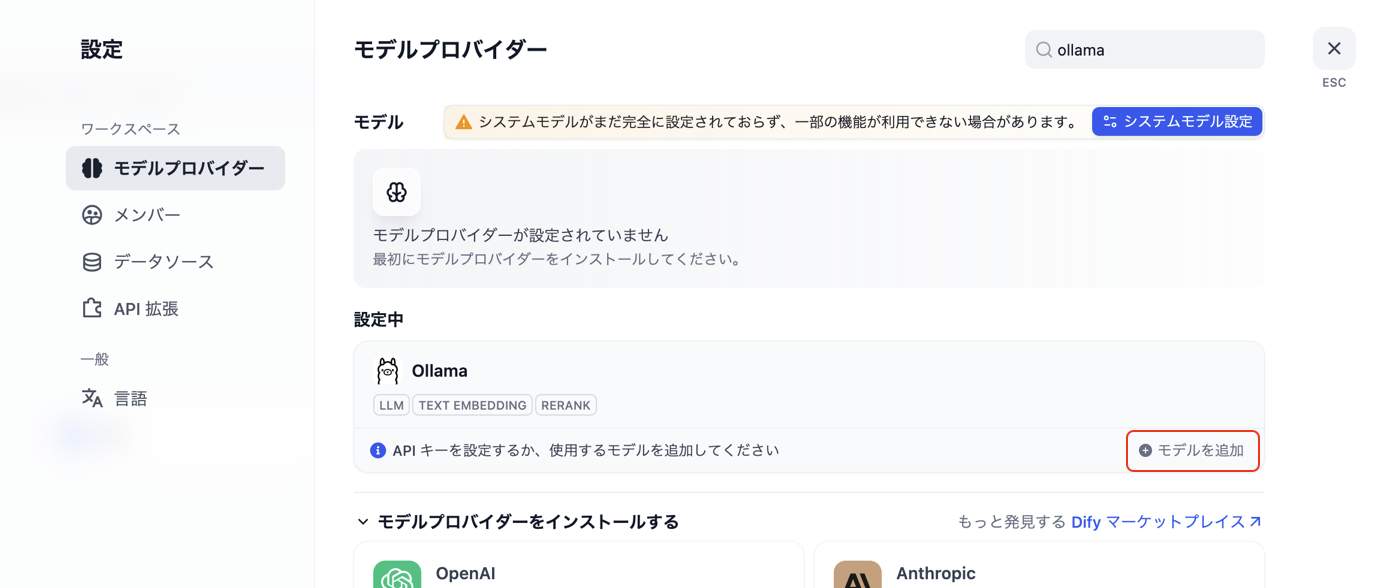
図. 「モデルを追加」ボタンをクリック
3.モデルの接続情報を入力して保存
- モデルの接続情報を入力します。
項目 内容 備考 Model Type LLM LLMモデルとしての登録になるので、「LLM」が選択された状態にします。 Model Name 実モデル名
例:
gpt-oss:20bollamaでインストールしたモデル名を入力します。
この例では「gpt-oss:20b」と入力します。
ローカルLLMのモデル比較Base URL
(dockerでローカル起動の場合)http://host.docker.internal:11434固定値として反映します。
Ollamaはローカルポート11434でAPIサービスを開始します。
https://docs.dify.ai/ja-jp/development/models-integration/ollamaVision support マルチモーダル対応の場合はYes 「gemma3:4b」「gemma3:12b」等の
マルチモーダル(画像分析)対応の場合はYesにします。この表を参考に入力して、「保存」ボタンをクリックします。
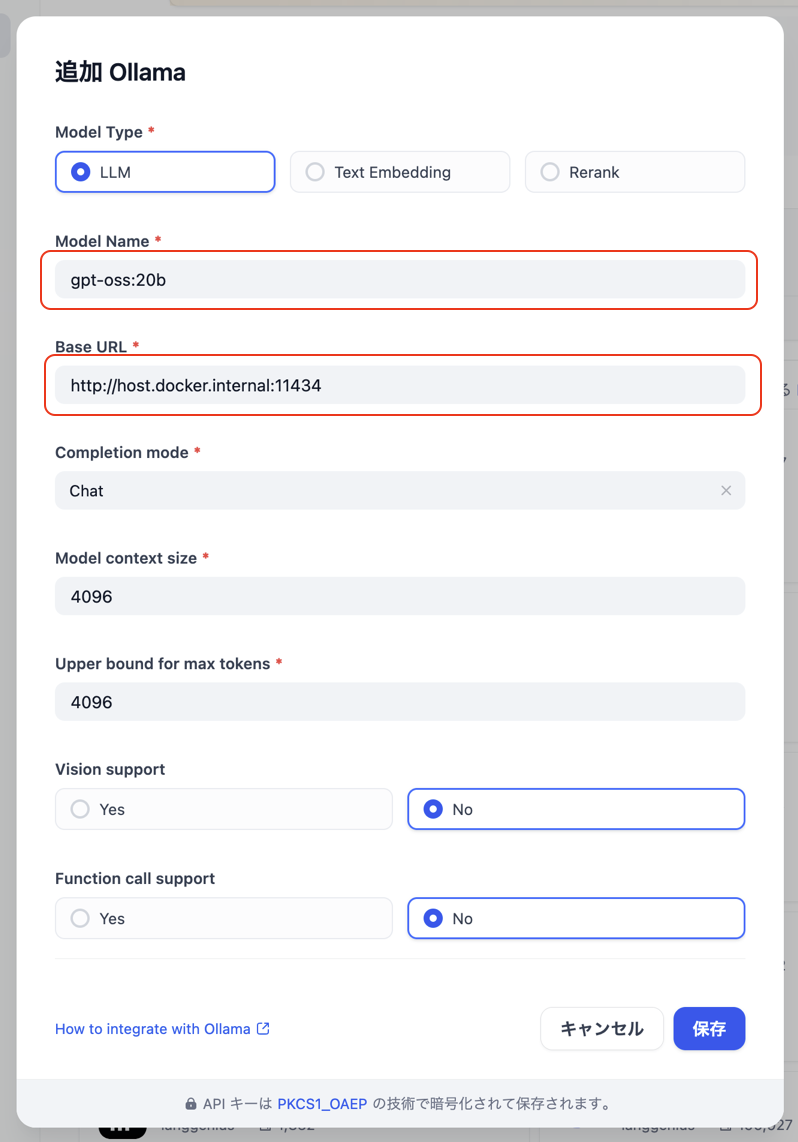
図. モデルの接続情報を入力 - 「モデルを表示」をクリックしたときに、設定したモデルが表示されていれば設定は成功です。
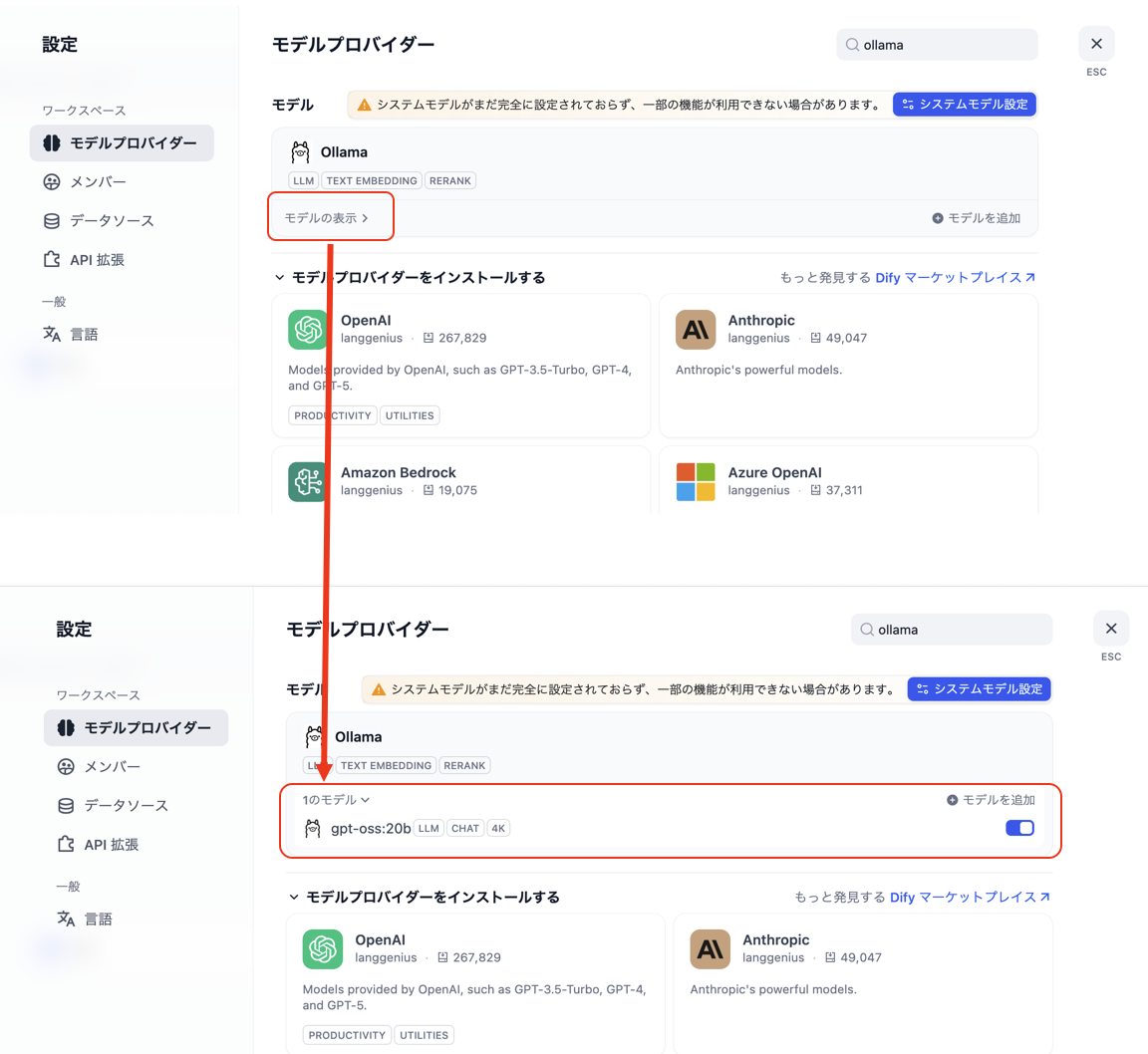
図. 設定したモデルを確認
関連記事
Categorys : ローカル LLMとの連携